对于人类来说,我们依赖大脑的听觉通路实现高效精准的语音信号处理,能够轻松实现每分钟300个汉字或者150个英文单词的自然语音识别。那么,如何建模大脑的听觉和语言环路并解析自然语音感知的神经机制?这是长久以来认知神经科学关注的重要问题。
如今,计算机科学家花费了数十年才终于实现了较为接近人类水平的自动语音识别AI模型。这类纯工程的AI模型彻底抛弃了早期基于语言学理论的模型框架,完全采用数据驱动的端到端大规模预训练深度神经网络。那么,这样的模型与人脑听觉通路有多少相似性呢?
针对这一问题,上海科技大学生物医学工程学院李远宁教授团队与加州大学旧金山分校Edward Chang教授及复旦大学吴劲松/路俊锋教授团队合作,融合自监督预训练深度语音模型、高密度颅内脑电、单神经元仿真模型等多种技术方法,在中英文跨语言对照实验范式下,深入研究了AI语音模型与人脑听觉通路在计算与表征上的相似性。
2023年10月30日,该研究成果以“Dissecting neural computations in the human auditory pathway using deep neural networks for speech”《运用深度神经网络语音模型解析人脑听觉通路的神经计算》为题在线发表于Nature子刊Nature Neuroscience[1]。

▷图 1:论文封面。图源:Nature Neuroscience官网
传统上,神经科学家会利用线性编码模型来研究神经环路的信息处理机制,所谓线性编码模型,主要是利用从语音中提取的特征来预测神经响应[2]。这些特征是基于语言学和音韵学的假设或理论来定义的。研究者可以在不同层次上提取特征——从纯声学的声谱图特征,到语音学的元辅音、构音方式,再到包含上下文信息的相对音高等,然后使用滑动时间窗口来预测神经响应。如果某类特征可以准确预测某个区域的神经活动,通常认为这个区域的神经活动编码表达了此类特征。
在过去的十多年中,运用颅内电生理记录实验的方式以及神经编码模型,研究者们已经发现了很多重要的神经编码的特征,例如,颞上回次级听觉皮层的不同神经群体的活动编码了从语音的包络、开头到具体的元辅音音素的特征等等[3](图2)。
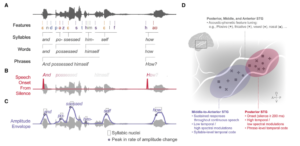
▷图 2:基于语言和语音学理论的语音特征提取以及神经编码模型。图源:参考文献3
在本项研究中,除了与语言密切相关的次级听觉皮层之外,运用颅内高密度脑电记录技术以及高精度的单神经元级别生物物理仿真模型,研究者获得了覆盖整个听觉通路的、从听神经到脑干再到听觉皮层的神经响应(图3)。虽然传统的基于理论驱动的神经编码研究可以分析通路中各个环节的编码信息,却难以融合成一整个能够实现高效精确语音识别的计算模型。
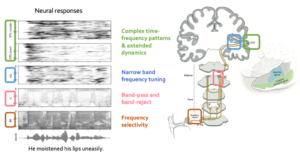
在人工智能领域,情况则恰恰相反。基于大规模自然语音训练的语音识别模型在很多自动语音识别(ASR)任务上已经达到接近人类的识别水平[4][5],但这类模型的内部特征表达呈现出复杂的动态模式(图4),其内在的表征与计算难以直接被理解与解释。
既然这些人工智能模型与大脑听觉回路能够接收相同的语音输入,并执行相似的认知功能,那么这两者之间是否存在计算和表征上的相似性呢?这便是这项研究聚焦的关键问题所在。
▷图 3:人脑听觉通路的自然语音神经响应活动记录,图中包含听神经(AN)-下丘(IC)-初级听觉皮层(HG)以及颞上回次级听觉皮层(STG)。图源:来自论文作者(李远宁)
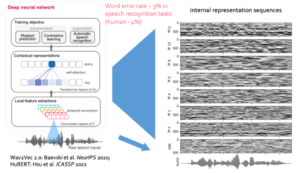
▷图 4:基于Transformer的深度语音模型(HuBERT)及其内部动态特征表达。图源:来自论文作者(李远宁)
为此,研究者通过构建一种新的深度神经编码模型来研究这个问题。这是一种纯数据驱动的模型,从语音预训练的深度神经网络中提取特征表达,运用这些数据驱动的特征构建新的线性编码模型,并与真实的大脑听觉响应信号进行相关性分析,从而研究深度神经网络内在特征表征与大脑听觉通路内不同神经群体活动之间的相似性。
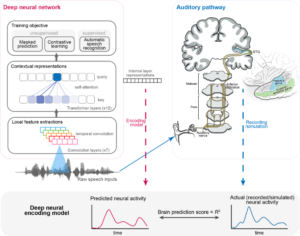
▷图 5:基本研究模型。基于预训练深度语音网络特征,构建神经编码模型,预测听觉通路的语音神经响应。图源:本论文
研究者在1000小时英文自然语音上训练了多种不同的人工智能模型,包括基于卷积(CNN)、LSTM以及Transformer等不同架构,运用对比学习、掩码预测等自监督训练和ASR有监督训练等不同训练方式。通过比较基于这些模型建立的神经编码模型在听觉通路不同节点的神经活动预测表现,研究发现,端到端的语音预训练网络的层级结构,与听觉回路的层级结构之间确实存在着很大的相似性(图6)。
首先,对于整个听觉通路,基于深度神经网络特征的编码预测模型要全面优于传统的基于语言学理论的线性特征模型。这说明整个听觉通路具有很强的非线性特征,即便是在传统认为高度线性化处理时频特征的听神经上,额外的非线性特征也可以极大地提升神经编码模型的预测准确性。
其次,不同复杂程度的模型对应于听觉通路中的不同区域:对于较为底层的听神经(AN)和丘脑(IC)神经活动来说,较为简单的卷积层即可较好地预测神经活动,而额外的Transformer结构并无法进一步提升预测准确度;而对于负责较为复杂语言信息加工处理的颞上回(STG),能够动态提取上下文信息的Transformer结构将显著地提升神经活动预测的准确性,而仅有静态有限感受域的卷积网络则无法与之相媲美。
此外,研究发现,对于同一个自监督语音模型,它的整体层级结构与听觉通路AN-IC-STG层级结构相对应,其中较为前端的卷积层更好地对应于听神经,而卷积输出层与前部Transformer层更好地对应于丘脑听觉神经元,颞上回次级听觉皮层则与中后部的Transformer层相对应。
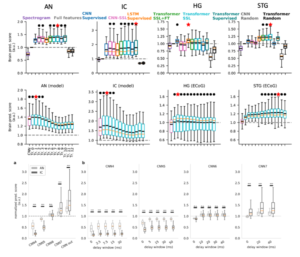
▷图 6:不同深度语音神经网络模型与听觉通路呈现不同对应关系。图源:本论文
在建立了深度语音模型与听觉通路的表征相似性之后,研究者进一步探究了驱动这些表征相似性的计算机制,并聚焦在表现性能最好的HuBERT模型上。这是一种类似BERT结构的Transformer模型,其中最重要的计算单元是自注意力机制[6](图7)。它的内部隐藏层的特征由skip connection和multi-head attention两部分叠加而成,skip connection反应的是当前时刻的序列状态,而attention则是上下文信息的加权组合。研究者通过分析注意力矩阵的权重信息来分析神经网络如何提取语音序列中的上下文特征。
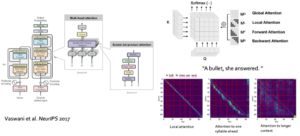
▷图 6:不同深度语音神经网络模型与听觉通路呈现不同对应关系。图源:本论文
依据音素(phonemic)和音节(syllabic)级别的语音上下文结构,研究者定义了随输入动态变化的自注意力模板。随后,使用实际的语音数据,研究者计算了Transformer预训练的网络的自注意力分布,究竟在多大程度上对齐到了这些上下文结构上。结果表明,随着网络的加深,对齐到长距离上下文结构的注意力权重也逐渐变大。值得强调的是,此处使用的HuBERT模型是完全自监督模型,训练过程不包含任何显式的上下文结构信息以及语音内容信息。这一结果表明,自监督训练的语音模型可以学习到自然语音中与语言和语义相关的关键上下文结构信息。
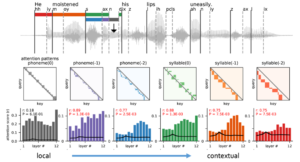
▷图 8:自监督学习模型从语料中学到语言相关的语音上下文结构信息。图源:本论文
这种通过自注意力计算获得的关键语音结构的准确性,是否与深度语音模型对大脑语音听觉皮层的相似性有关呢?研究者将这两者进行了相关性分析,结果表明(图9):在与语音处理密切相关的颞上回次级听觉皮层,这两者呈现显著的正相关,也就是说,自注意力权重与语音中的上下文结构对齐程度越高,神经网络对于大脑活动的预测能力就越强;而反之,在初级听觉皮层以及听神经、脑干这些区域,这两者则是负相关,说明对上下文注意的越少,即对时域上局部瞬态信息的表达越多,神经网络与大脑信号的相似度也就越高。因此,通过自注意力机制对语音上下文信息的动态提取的过程,是解释自监督深度语音模型与大脑听觉通路表征相似性的关键计算机制。

▷图 9:自注意力机制与语音上下文结构的对齐程度解释了深度神经模型对听觉通路语音响应的预测能力。图源:本论文
最后,研究进一步分析了自监督模型是否能够学习到更高层级的上下文信息,通过跨语言比较这一独特的范式[7],分析了深度神经网络与大脑听觉皮层的语言特异性。为了模拟母语者的语言特异性,研究使用了在英文数据上预训练的英文语音模型,以及在中文数据上预训练的中文语音模型(图10)。
如果仅仅使用线性时频编码模型,也就是STRF model,是无法体现出英文母语者在听英文和听中文时候的语言特异性的,这一点在研究者的前期研究中也验证过,底层声学信息的处理是跨语言通用的。但是如果用英文预训练神经网络来预测神经活动,则可以体现英文母语者对不同语言语音的特异性响应,英文模型更好地预测听英文时的神经响应,并且模型注意力权重与英文的上下文结构信息的对齐程度,与模型性能显著正相关。类似地,如果使用中文预训练模型预测中文母语者的听觉皮层神经响应,则可以体现中文母语者对不同语言语音的特异性响应,中文模型更好地预测听中文时的神经响应,并且模型注意力权重与中文的上下文结构信息的对齐程度,与模型性能显著正相关。
这一双重分离的结果表明,自监督模型能够学习到更高层级的与语言特异性相关的上下文信息,并且这一特异性信息与大脑语音皮层的计算与表征是显著相关的。
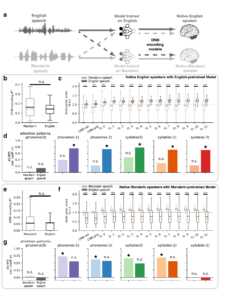
▷图 10:不同语言预训练的语音神经网络体现出语言特异性的计算与表征,并与次级听觉皮层的语言特异性神经活动呈现显著对应关系。图源:本论文
▷图 10:不同语言预训练的语音神经网络体现出语言特异性的计算与表征,并与次级听觉皮层的语言特异性神经活动呈现显著对应关系。图源:本论文
从神经科学的角度来看,这项研究与近期发表的多项相关研究[8][9][10]共同提出了基于大规模自监督模型建立语言相关的认知功能计算模型的新思路,展现了自监督语音模型与大脑听觉通路的计算与表征的相似性。从人工智能的角度,这项研究也为打开深度神经网络,特别是自注意力模型Transformer的“黑箱”提供了新的生物学视角。
上海科技大学生物医学工程学院李远宁研究员为本文第一作者,加州大学旧金山分校神经外科Edward Chang教授为本文通讯作者,复旦大学附属华山医院吴劲松教授、路俊锋教授,上海科技大学研究生陈佩利参与了此项研究,该研究参与者还包括来自加州大学伯克利分校、Meta AI以及罗彻斯特大学的研究者。