Since the end of 2022, ChatGPT has swept across the globe like a tidal wave, and people are eagerly anticipating its potential applications. Business professionals, scholars, and even ordinary individuals are pondering the same question: How will AI shape the future of our work?
As time goes by, many concepts are gradually becoming reality. Humanity seems to have grown accustomed to AI assisting us or even replacing us in many work scenarios. Early fears about GPT have gradually dissipated; instead, people have become overly reliant on GPT, even overlooking possible limitations and risks. We refer to this excessive dependence on GPT while ignoring its risks as “GPTology.”
The development of psychology has always closely followed technological innovation. Sociologists and behavioral scientists have consistently leveraged technology to collect rich and diverse data. Technologies ranging from neuroimaging and online survey platforms to eye-tracking devices have all contributed to critical breakthroughs in psychology. The digital revolution and the rise of big data have fostered new disciplines like computational social science. Just as in other fields (medicine [1], politics [2]), large language models (LLMs) that can understand, generate, and translate human language with astonishing subtlety and complexity have also had a profound impact on psychology.
In psychology, there are two main applications for large language models: On one hand, studying the mechanisms of LLMs themselves may provide new insights into human cognition. On the other hand, their capabilities in text analysis and generation make them powerful tools for analyzing textual data. For example, they can transform textual data such as individuals’ written or spoken expressions into analyzable data forms, thereby assisting mental health professionals in assessing and understanding an individual’s psychological state. Recently, numerous studies have emerged using large language models to advance psychological research. Applications of ChatGPT in social and behavioral sciences, such as hate speech classification and sentiment analysis, have shown promising initial results and have broad development prospects.
However, should we allow the current momentum of “GPTology” to run rampant in the research field? In fact, the integration process of all technological innovations is always full of turbulence. Allowing unchecked application of a certain technology and becoming overly reliant on it may lead to unexpected consequences. Looking back at the history of psychology, when functional magnetic resonance imaging (fMRI) technology first emerged, some researchers abused it, leading to absurd yet statistically significant neural association phenomena—for instance, researchers performed an fMRI scan on a dead Atlantic salmon and found that the fish displayed significant brain activity during the experiment. Other studies have indicated that due to statistical misuse, the likelihood of finding false correlations in fMRI research is extremely high. These studies have entered psychology textbooks, warning all psychology students and researchers to remain vigilant when facing new technologies.

▷ Abdurahman, Suhaib, et al. “Perils and opportunities in using large language models in psychological research.” PNAS Nexus 3.7 (2024): pgad245.
We can say that we have entered a “cooling-off period” in our relationship with large language models. Besides considering what large language models can do, we need to reflect more on whether and why we should use them. A recent review paper in PNAS Nexus explores the application of large language models in psychological research and the new opportunities they bring to the study of human behavior.
The article acknowledges the potential utility of LLMs in enhancing psychology but also emphasizes caution against their uncritical application. Currently, these models may cause statistically significant but meaningless or ambiguous correlations in psychological research, which researchers must avoid. The authors remind us that, in the face of similar challenges encountered in recent decades (such as the replication crisis), researchers should be cautious in applying LLMs. The paper also proposes directions on how to use these models more critically and prudently in the future to advance psychological research.
1. Can Large Language Models Replace Human Subjects?
When it comes to large language models (LLMs), people’s most intuitive impression is of their highly “human-like” output capabilities. Webb et al. examined ChatGPT’s analogical reasoning abilities [3] and found that it has already exhibited zero-shot reasoning capabilities, able to solve a wide range of analogical reasoning problems without explicit training. Some believe that if LLMs like ChatGPT can indeed produce human-like responses to common psychological measurements—such as judgments of actions, value endorsements, and views on social issues—they may potentially replace human subject groups in the future.
Addressing this question, Dillon and colleagues conducted a dedicated study [4]. They first compared the moral judgments of humans and the language model GPT-3.5, affirming that language models can replicate some human judgments. However, they also highlighted challenges in interpreting language model outputs. Fundamentally, the “thinking” of LLMs is built upon human natural expressions, but the actual population they represent is limited, and there is a risk of oversimplifying the complex thoughts and behaviors of humans. This serves as a warning because the tendency to anthropomorphize AI systems may mislead us into expecting these systems—operating on fundamentally different principles—to exhibit human-like performance.
Current research indicates that using LLMs to simulate human subjects presents at least three major problems.
First, cross-cultural differences in cognitive processes are an extremely important aspect of psychological research, but much evidence shows that current popular LLMs cannot simulate such differences. Models like GPT are mainly trained on text data from WEIRD (Western, Educated, Industrialized, Rich, Democratic) populations. This English-centric data processing continues the English centralism in psychology, running counter to expectations of linguistic diversity. As a result, language models find it difficult to accurately reflect the diversity of the general population. For example, ChatGPT exhibits gender biases favoring male perspectives and narratives, cultural biases favoring American viewpoints or majority populations, and political biases favoring liberalism, environmentalism, and left-libertarian views. These biases also extend to personality traits, morality, and stereotypes.
Overall, because the model outputs strongly reflect the psychology of WEIRD populations, high correlations between AI and human responses cannot be reproduced when human samples are less WEIRD. In psychological research, over-reliance on WEIRD subjects (such as North American college students) once sparked discussions. Replacing human participants with LLM outputs would be a regression, making psychological research narrower and less universal.
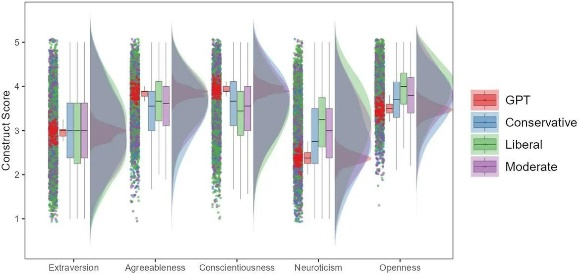
▷ Comparing ChatGPT’s responses to the “Big Five” personality traits with human responses grouped by political views. Note: The figure shows the distribution of responses from humans and ChatGPT on the Big Five personality dimensions and different demographic data. ChatGPT gives significantly higher responses in agreeableness and conscientiousness and significantly lower responses in openness and neuroticism. Importantly, compared to all demographic groups, ChatGPT shows significantly smaller variance across all personality dimensions.
Second, LLMs seem to have a preference for “correct answers.” They exhibit low variability when answering psychological survey questions—even when the topics involved (such as moral judgments) do not have actual correct answers—while human responses to these questions are often diverse. When we ask LLMs to answer the same question multiple times and measure the variance in their answers, we find that language models cannot produce the significant ideological differences that humans do. This is inseparable from the principles behind generative language models; they generate output sequences by calculating the probability distribution of the next possible word in an autoregressive manner. Conceptually, repeatedly questioning an LLM is similar to repeatedly asking the same participant, rather than querying different participants.
However, psychologists are usually interested in studying differences between different participants. This warns us that when attempting to use LLMs to simulate human subjects, we cannot simply use language models to simulate group averages or an individual’s responses across different tasks. Appropriate methods should be developed to truly reproduce the complexity of human samples. Additionally, the data used to train LLMs may already contain many items and tasks used in psychological experiments, causing the model to rely on memory rather than reasoning when tested, further exacerbating the above issues. To obtain an unbiased evaluation of LLMs’ human-like behavior, researchers need to ensure that their tasks are not part of the model’s training data or adjust the model to avoid affecting experimental results, such as through methods like “unlearning.”
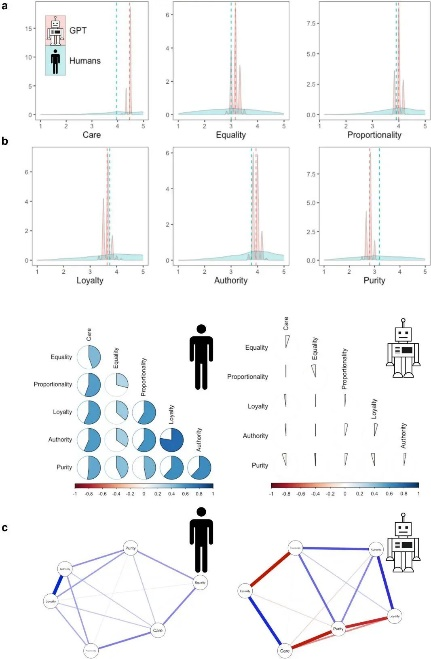
Finally, it is questionable whether GPT has truly formed a moral system similar to that of humans. By querying the LLM and constructing its internal nomological network—observing the correlations between different moral domains—it was found that these metrics differ significantly from results obtained from humans.
▷ ChatGPT and Human Moral Judgments. Note: a) Distributions of human moral judgments (light blue) and GPT (light red) across six moral domains. Dashed lines represent means. b) Interrelationships between human moral values (N=3,902) and ChatGPT responses (N=1,000). c) Partial correlation networks among moral values based on different human samples from 19 countries (30) and 1,000 GPT responses. Blue edges indicate positive partial correlations; red edges indicate negative partial correlations.
In summary, LLMs ignore population diversity, cannot exhibit significant variance, and cannot replicate nomological networks—these shortcomings indicate that LLMs should not replace studies on Homo sapiens. However, this does not mean that psychological research should completely abandon the use of LLMs. On the one hand, applying psychological measurements traditionally used for humans to AI is indeed interesting, but interpretations of the results should be more cautious. On the other hand, when using LLMs as proxy models to simulate human behavior, their intermediate layer parameters can provide potential angles for exploring human cognitive behavior. However, this process should be conducted under strictly defined environments, agents, interactions, and outcomes.
Due to the “black box” nature of LLMs and the aforementioned situation where their outputs often differ from real human behavior, this expectation is still difficult to realize. But we can hope that in the future, more robust programs can be developed, making it more feasible for LLMs to simulate human behavior in psychological research.
2. Are Large Language Models a Panacea for Text Analysis?
Apart from their human-like qualities, the most significant feature of large language models (LLMs) is their powerful language processing capability. Applying natural language processing (NLP) methods to psychological research is not new. To understand why the application of LLMs has sparked considerable controversy today, we need to examine how their use differs from traditional NLP methods.
NLP methods utilizing pre-trained language models can be divided into two categories based on whether they involve parameter updates. Models involving parameter updates are further trained on specific task datasets. In contrast, zero-shot learning, one-shot learning, and few-shot learning do not require gradient updates; they directly leverage the capabilities of the pre-trained model to generalize from limited or no task-specific data, completing tasks by utilizing the model’s existing knowledge and understanding.
The groundbreaking leap in LLM capabilities—for example, their ability to handle multiple tasks without specific adjustments and their user-friendly designs that reduce the need for complex coding—has led to an increasing number of studies applying their zero-shot capabilities* to psychological text analysis, including sentiment analysis, offensive language detection, mindset assessment, and emotion detection.
*The zero-shot capability of LLMs refers to the model’s ability to understand and perform new tasks without having been specifically trained or optimized for those tasks. For example, a large language model can recognize whether a text is positive, negative, or neutral by understanding its content and context, even without targeted training data.
However, as applications deepen, more voices are pointing out the limitations of LLMs. First, LLMs may produce inconsistent outputs when faced with slight variations in prompts, and when aggregating multiple repeated outputs to different prompts, LLMs sometimes fail to meet the standards of scientific reliability. Additionally, Kocoń et al. [5] found that LLMs may encounter difficulties when handling complex, subjective tasks such as sentiment recognition. Lastly, reflecting on traditional fine-tuned models, the convenience of zero-shot applications of LLMs may not be as significantly different from model fine-tuning as commonly believed.
We should recognize that small language models fine-tuned for various tasks are also continuously developing, and more models are becoming publicly available today. Moreover, an increasing number of high-quality and specialized datasets are available for researchers to fine-tune language models. Although the zero-shot applications of LLMs may provide immediate convenience, the most straightforward choice is often not the most effective one, and researchers should maintain necessary caution when attracted by convenience.
To observe ChatGPT’s capabilities in text processing more intuitively, researchers set up three levels of models: zero-shot, few-shot, and fine-tuned, to extract moral values from online texts. This is a challenging task because even trained human annotators often disagree. The expression of moral values in language is usually extremely implicit, and due to length limitations, online posts often contain little background information. Researchers provided 2,983 social media posts containing moral or non-moral language to ChatGPT, asking it to judge whether the posts used any specific types of moral language. They then compared it with a small BERT model fine-tuned on a separate subset of social media posts, using human evaluators’ judgments as the standard.
The results showed that the fine-tuned BERT model performed far better than ChatGPT in the zero-shot setting; BERT achieved an F1 score of 0.48, while ChatGPT only reached 0.22. Even methods based on LIWC surpassed ChatGPT (zero-shot) in F1 score, reaching 0.27. ChatGPT exhibited extremely extreme behavior in predicting moral sentiments, while BERT showed no significant differences from trained human annotators in almost all cases.
Although LIWC is a smaller, less complex, and less costly model, its likelihood and extremity of deviating from trained human annotators are significantly lower than those of ChatGPT. As expected, few-shot learning and fine-tuning both improved ChatGPT’s performance in the experiment. We draw two conclusions. First, the cross-contextual and flexibility advantages claimed by LLMs may not always hold. Second, although LLMs are very convenient as “plug-and-play,” they may sometimes fail completely, and appropriate fine-tuning can mitigate these issues.
▷ Jean-Michel Bihorel
In addition to inconsistencies in text annotation, inadequacies in explaining complex concepts (such as implicit hate speech), and possible lack of depth in specialized or sensitive domains, the lack of interpretability is also a much-criticized aspect of LLMs. As powerful language analysis tools, LLMs derive their extensive functions from massive parameter sets, training data, and training processes. However, this increase in flexibility and performance comes at the cost of reduced interpretability and reproducibility. The so-called stronger predictive power of LLMs is an important reason why researchers in psychological text analysis tend to use neural network–based models. But if they cannot significantly surpass top-down methods, the advantages in interpretability of the latter may prompt psychologists and other social scientists to turn to more traditional models.
Overall, in many application scenarios, smaller (fine-tuned) models can be more powerful and less biased than current large (generative) language models. This is especially true when large language models are used in zero-shot and few-shot settings. For example, when exploring the language of online support forums for anxiety patients, researchers using smaller, specialized language models may be able to discover subtle details and specific language patterns directly related to the research field (e.g., worries, tolerance of uncertainty). This targeted approach can provide deeper insights into the experiences of anxiety patients, revealing their unique challenges and potential interventions. By leveraging specialized language models or top-down methods like CCR and LIWC, researchers can strike a balance between breadth and depth, enabling a more nuanced exploration of text data.
Nevertheless, as text analysis tools, LLMs may still perform valuable functions in cases where fine-tuning data is scarce, such as emerging concepts or under-researched groups. Their zero-shot capabilities enable researchers to explore pressing research topics. In these cases, adopting few-shot prompting methods may be both effective and efficient, as they require only a small number of representative examples.
Moreover, studies have shown that LLMs can benefit from theory-driven methods. Based on this finding, developing techniques that combine the advantages of both approaches is a promising direction for future research. With the rapid advancement of large language model technology, solving performance and bias issues is only a matter of time, and it is expected that these challenges will be effectively alleviated in the near future.
3. Reproducibility Cannot Be Ignored
Reproducibility refers to the ability to replicate and verify results using the same data and methods. However, the black-box nature of LLMs makes related research findings difficult to reproduce. For studies that rely on data or analyses generated by LLMs, this limitation poses a significant obstacle to achieving reproducibility.
For example, after an LLM is updated, its preferences may change, potentially affecting the effectiveness of previously established “best practices” and “debiasing strategies.” Currently, ChatGPT and other closed-source models do not provide their older versions, which limits researchers’ ability to reproduce results using models from specific points in time. For instance, once the “gpt-3.5-January-2023” version is updated, its parameters and generated outputs may change, challenging the rigor of scientific research. Importantly, new versions do not guarantee the same or better performance on all tasks. For example, GPT-3.5 and GPT-4 have been reported to produce inconsistent results on various text analysis tasks—GPT-4 sometimes performs worse than GPT-3.5 [6]—which further deepens concerns about non-transparent changes in the models.
Beyond considering the black-box nature of LLMs from the perspective of open science, researchers are more concerned with the scientific spirit of “knowing what it is and why it is so.” When obtaining high-quality and informative semantic representations, we should focus more on the algorithms used to generate these outputs rather than the outputs themselves. In the past, one of the main advantages of computational models was that they allowed us to “peek inside”; certain psychological processes that are difficult to test can be inferred through models. Therefore, using proprietary LLMs that do not provide this level of access may hinder researchers in psychology and other fields from benefiting from the latest advances in computational science.
▷ Stuart McReath
4. Conclusion
The new generation of online service-oriented large language models (LLMs) developed for the general public—such as ChatGPT, Gemini, and Claude—provides many researchers with tools that are both powerful and easy to use. However, as these tools become more popular and user-friendly, researchers have a responsibility to maintain a clear understanding of both the capabilities and limitations of these models. Particularly in certain tasks, the excellent performance and high interactivity of LLMs may lead people to mistakenly believe that they are always the best choice as research subjects or automated text analysis assistants. Such misconceptions can oversimplify people’s understanding of these complex tools and result in unwise decisions. For example, avoiding necessary fine-tuning for the sake of convenience or due to a lack of understanding may prevent full utilization of their capabilities, ultimately leading to relatively poor outcomes. Additionally, it may cause researchers to overlook unique challenges related to transparency and reproducibility.
We also need to recognize that many advantages attributed to LLMs exist in other models as well. For instance, BERT or open-source LLMs can be accessed via APIs, providing researchers who cannot self-host these technologies with a convenient and low-cost option. This enables these models to be widely used without requiring extensive coding or technical expertise. Additionally, OpenAI offers embedding models like “text-embedding-ada-003,” which can be used for downstream tasks similar to BERT.
Ultimately, the responsible use of any computational tool requires us to fully understand its capabilities and carefully consider whether it is the most suitable method for the current task. This balanced approach ensures that technological advances are utilized effectively and responsibly in research.