“Will machines eventually surpass humans?” This question has become even more thought-provoking in 2024. Just as we marvel at the intricate mechanisms of the human brain, artificial intelligence is expanding the boundaries of what is possible at an astonishing pace. From clinical diagnostics to mathematical proofs, and from virus discovery to drug development, AI is redefining the frontiers of human intelligence.
Over the past year, we have witnessed several game-changing breakthroughs in AI. In ophthalmic diagnostics, AI has achieved expert-level performance for the first time. In tackling Olympiad-level geometry problems, AlphaGeometry has produced elegant proofs without any human intervention. And in the realm of weather forecasting, GenCast has pushed traditional predictive models beyond their limits. These accomplishments naturally prompt us to ask: where exactly are the boundaries of AI’s capabilities? Has it begun to truly understand rather than merely mimic?
Yet, these advances have also revealed a series of deep-seated contradictions: as models grow larger, their reliability sometimes declines; systems that claim to be open, in fact, form new technological monopolies; and in critical fields like healthcare, even though AI demonstrates potential that surpasses human abilities, it still struggles to fully replace human intuitive judgment. This very paradox underscores an important truth: the progress of AI should not aim to replace human beings, but rather to explore how to optimally complement human intelligence.
In this era of rapidly evolving human–machine collaboration, let us break free from binary thinking and reconsider: what is the true meaning of technological progress? How can we strike a balance between breakthrough innovation and ethical safety?
With these questions in mind, let us delve into the top ten advances in AI research for 2024 and explore these groundbreaking discoveries that are reshaping the future of humanity.
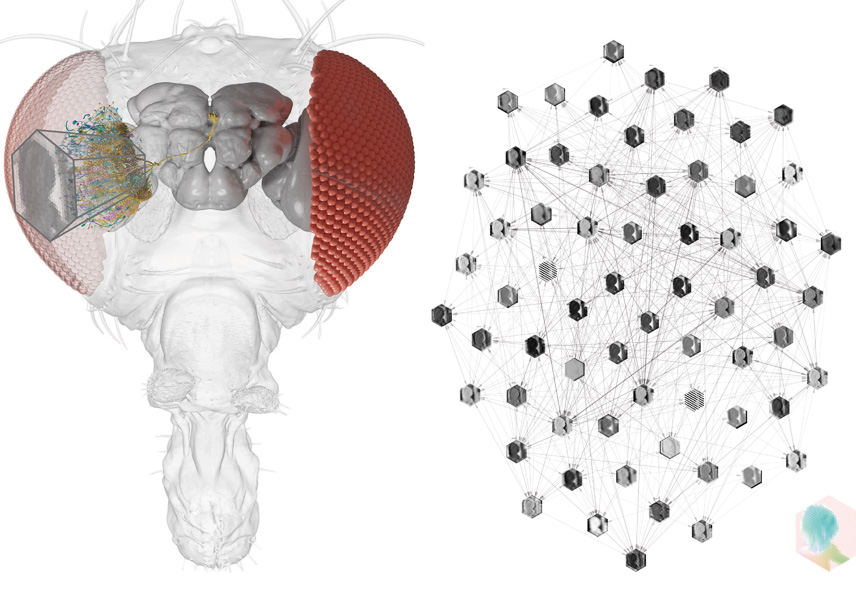
10. Connectome-Constrained Networks Predict Neural Activity in the Fly Visual System
Reference: Lappalainen, J.K., Tschopp, F.D., Prakhya, S., et al. Connectome-constrained networks predict neural activity across the fly visual system. Nature. 2024;634(1):89–97. doi:10.1038/s41586-024-07939-3
A long-standing challenge in neuroscience has been to elucidate the functional mechanisms underlying neural computation using the known neuronal connectome. Lappalainen et al. sought to answer the question: Can connectome data predict the dynamic activity of the nervous system when network models are constrained by neural connectivity?
In a study published in Nature, a collaborative team from Harvard University and the University of Cambridge provided an affirmative answer by investigating the fly’s visual motion pathway. Using a complete connectome dataset encompassing 64 cell types in the fly visual system, the researchers built a model that relied solely on synaptic connectivity information and did not depend on neuronal dynamic parameters. By employing deep learning to optimize unknown parameters—such as synaptic strengths and neuronal activation thresholds—the model successfully predicted neural activity patterns associated with visual motion detection in fruit flies, demonstrating high consistency with 26 independent experimental observations. Furthermore, the study revealed that the sparse connectivity characteristic of neural networks—a feature commonly observed across species—was key to the model’s predictive success. This sparsity reduced the complexity of parameter optimization, enabling the inference of dynamic mechanisms without the need for in vivo measurements.
Academic Impact:
(1)Theoretical Breakthrough: For the first time, it has been demonstrated that connectome data is sufficient to predict dynamic neural activity, challenging the conventional notion that dynamic parameters are indispensable.
(2)Technological Innovation: The integration of deep learning with connectomics provides a universal tool for modeling complex neural systems.
(3)Cross-Species Implications: The widespread presence of sparse connectivity suggests that this strategy may be extendable to studies of mammalian and even human brains.
(4)Experimental Paradigm: The introduction of a “connectome-constrained modeling” approach accelerates the generation of hypotheses regarding the functional mechanisms of neural circuits.
▷ Comparison of student generalization performance as a function of teacher predictability under the Consolidation model (left) and the Go-CLS model (right).
09.Designing Easily-Synthesizable and Structurally Novel Antibiotics: How Generative AI Plays a Role
Reference: Swanson, K., Liu, G., Catacutan, D. B., Arnold, A., Zou, J., & Stokes, J. M. (2024). Generative AI for designing and validating easily synthesizable and structurally novel antibiotics. Nature Machine Intelligence, 6(3), 338–353.
In face of an escalating threat from multidrug-resistant bacteria, there is an urgent need for antibiotics that are both structurally novel and easy to synthesize. However, traditional drug discovery is hampered by the inefficiency in exploring chemical space and by high synthesis costs. Drug development has always been challenging—now, with the assistance of generative AI, can we overcome the synthesizability challenge in antibiotic research?
In a study published in Nature Machine Intelligence, a team from Stanford University and McMaster University developed a generative AI model called SyntheMol, which directly designs synthesizable, novel candidate molecules from a compound library of nearly 30 billion molecules. Targeting the highly drug-resistant Acinetobacter baumannii, the team synthesized 58 AI-generated molecules. Among these, 6 demonstrated broad-spectrum antibacterial activity (targeting pathogens such as Klebsiella pneumoniae), and 2 passed toxicity tests in mice. By constraining the generative logic—for instance, by limiting synthesis steps to no more than five and avoiding rare reagents—SyntheMol boosted the design success rate to 10% (compared to the typical rate of less than 1% with traditional methods), achieving, for the first time, simultaneous optimization of novelty, synthesizability, and efficacy. Can generative AI truly unlock the synthesizability challenge in antibiotic development?
Academic Impact:
(1)Technological Paradigm Shift: Generative AI bypasses the conventional “predict-and-screen” process by directly producing synthesizable molecules, thereby shortening the development cycle.
(2)Breakthrough in Combating Drug Resistance: The novel molecules target “superbugs” such as Acinetobacter baumannii, filling the existing gap in antibiotic structures.
(3)Cost Revolution: By simplifying synthesis pathways and reducing production costs, this approach enhances drug accessibility in low- and middle-income countries.
(4)Open-Source Collaboration Potential: Open-sourcing of models and data accelerates the global development of anti-infective drugs.
08. Scaling Up and Instruction Tuning in LLMs Undermine Their Reliability
Reference: Zhou L, Schellaert W, Martínez-Plumed F, et al. Larger and more instructable language models become less reliable. Nature. 2024;634(1):61–68. doi:10.1038/s41586-024-07930-y
In the field of artificial intelligence, the prevailing paradigm has long been that “bigger is better” when it comes to model development. However, we now face the question: can increasing model size and optimizing instructions come at the expense of reliability?
In a study published in Nature, a team from the Polytechnic University of Valencia in Spain analyzed major model families such as GPT, LLaMA, and BLOOM, revealing the hidden costs associated with scaling and instruction tuning. The research found that as the number of model parameters and the volume of training data increased, the error rate on simple tasks did not decrease as expected; in fact, it increased. For example, GPT-4 exhibits an error rate of over 60% on basic arithmetic problems and tends to generate answers that seem plausible but are incorrect, rather than using the “refusal to answer” strategy observed in earlier models. This “brain fog” phenomenon (i.e., intermittent cognitive impairment) is particularly pronounced in low-difficulty tasks. Although the optimized models can address a wider range of questions, the distribution of errors becomes unpredictable, making it difficult for users to gauge reliability based on task difficulty. The study further noted that the models exhibit stability fluctuations when faced with different phrasings of the same question, indicating that the current optimization strategies have not addressed the fundamental flaws.
Academic Impact:
(1)Technological Paradigm Disruption: Challenges the industry consensus that “bigger is better,” revealing that scaling up may lead to a disconnect between enhanced capabilities and reliability.
(2)Erosion of User Trust: The deceptively plausible errors undermine human oversight, thereby increasing the risk of misuse in high-stakes domains such as healthcare and legal systems.
(3)Need for Ethical Governance: There is a pressing need to establish standards for model transparency and dynamic confidence mechanisms to balance performance gains with controllability.
07. Using Artificial Intelligence to Document the Hidden RNA Virosphere
Reference: Hou X, He Y, Fang P, et al. Using Artificial Intelligence to Document the Hidden RNA Virosphere. Cell. 2024;187(1):1–14. doi:10.1016/j.cell.2024.09.027
Traditional virology methods, which rely on homology comparisons with known sequences, have long struggled to capture the “dark matter” of highly divergent RNA viruses. Can AI, utilizing new tools, reveal the hidden facets of the RNA virosphere?
In a study published in Cell, a team from Sun Yat-sen University and Alibaba Cloud developed a deep learning model named LucaProt. By integrating sequence data with predicted protein structural features, the model mined over 160,000 novel RNA viruses from more than 10,000 environmental samples worldwide, including 23 entirely novel viral clades. These viruses have been found in extreme environments (such as deep-sea hydrothermal vents), and some possess genome lengths that far exceed known limits—completely overturning our understanding of RNA virus ecological adaptability. Through interdisciplinary collaboration, which combined biological validation with AI model optimization, the study confirms that AI can overcome the blind spots of traditional methods, offering a powerful new tool for virus taxonomy and epidemic early warning.
Academic Impact:
(1)Technological Paradigm Revolution: AI-driven virus discovery has expanded the known diversity of RNA viruses by nearly 30-fold, reshaping the virus classification system.
(2)Ecological Theoretical Breakthrough: The active replication of viruses in extreme environments challenges conventional host–environment interaction models.
(3)Public Health Preparedness: The repository of unknown viruses provides a crucial data foundation for monitoring potential pathogens and accelerating vaccine development.
(4)Open-Source Collaboration Value: Global sharing of models and data fosters interdisciplinary collaboration and accelerates innovative research.
06. Why Is “Open” AI Still Closed?
Reference: Gray Widder D, Whittaker M, West SM. Why ‘Open’ AI Systems Are Actually Closed, and Why This Matters. Nature. 2024;626(1):107–113. doi:10.1038/s41586-024-08141-1
The touted commitment to “openness” in artificial intelligence is often seen as the cornerstone of technological democratization, yet its actual practice diverges sharply from this ideal. For example, OpenAI—a pioneer in AI bearing the name “Open”—finds itself unable to break free from technological monopolies and closed systems.
In a recent study published in Nature, a team from institutions including Cornell University and the Massachusetts Institute of Technology systematically analyzed models such as Meta’s LLaMA and Mistral AI’s Mixtral. They revealed three distinct dimensions of closure in “open” AI systems: technical closure (opaque training data and code), ecological closure (reliance on major cloud computing platforms), and power closure (entrenched market entry barriers). The research found that even when some model weights are made public, companies retain control through restrictive agreements (for example, banning military applications) and infrastructural monopolies (such as integration with Azure). This phenomenon of “openwashing” severely limits external scrutiny and innovation, while the so-called “open source” becomes a tool for large corporations to appropriate community contributions and consolidate their monopolies.
Academic Impact:
(1)Defining Technological Boundaries: Redefining the standard of “openness” by emphasizing that transparency must cover the entire chain—from data and algorithms to computational resources, not merely model weights.
(2)Innovation in Governance Models: Advocating for policies that mandate the disclosure of training data metadata (such as sources and selection criteria) and restrict the monopolistic practices of cloud computing platforms.
(3)Pathways to Ecological Reconstruction: Supporting decentralized public computing resources (for example, the EU supercomputer) and upgrading open-source licenses to break the cycle of commercial closed-loop dependencies.
(4)Balancing Safety and Innovation: Establishing a dynamic regulatory framework for open models that mitigates misuse risks while unleashing the community’s innovative potential.
05. Machine Independently Solves Olympiad Geometry Problems
Reference: Trinh, T. H., Luong, T. D., et al. Solving olympiad geometry without human demonstrations. Nature. 626, 107–113 (2024). doi:10.1038/s41586-023-06747-5
The automation of mathematical theorem proving has long been hindered by two major bottlenecks: first, converting human proofs into machine-verifiable forms is extremely costly; second, the field of geometry suffers from a severe scarcity of training data due to its reliance on diagrammatic representation and unstructured logic. How can artificial intelligence overcome the dual challenges of data scarcity and the limitations of symbolic reasoning in the automated proving of complex geometric problems?
In a study published in Nature, the DeepMind team introduced the AlphaGeometry system—a neuro-symbolic integrated architecture that, for the first time, achieves Olympiad-level geometry problem solving without human demonstrations. The system employs a symbolic deduction engine to generate 100 million synthetic theorems and their proofs, thereby constructing a self-supervised training dataset. It also trains a neural language model to predict strategies for auxiliary constructions, guiding the symbolic engine through infinite branching points. In tests on 30 recent Olympiad geometry problems, AlphaGeometry solved 25 problems (compared to only 10 solved by the previous best system). It nearly matched the average performance of International Mathematical Olympiad (IMO) gold medalists and produced human-readable proofs.
Academic Impact:
(1)Theoretical Breakthrough: For the first time, the effectiveness of neuro-symbolic collaboration in formal mathematics has been validated, offering a new paradigm for solving challenging STEM problems.
(2)Technological Innovation: The synthetic data generation framework overcomes the data bottleneck in the field and can be extended to other branches such as topology and combinatorics.
(3)Educational Potential: It provides intelligent assistance tools for math competition training and personalized learning, fostering an “AI-human collaborative proof” model.
(4)Fundamental Science: It reveals the complementarity between intuitive insight and rigorous deduction in geometric reasoning, promoting interdisciplinary research between cognitive science and AI.
04. Randomized Clinical Trial: The Impact of LLM on Diagnostic Reasoning
Reference: Goh E, Gallo R, Hom J, et al. Large Language Model Influence on Diagnostic Reasoning: A Randomized Clinical Trial. JAMA Network Open. 2024; 7(10): e2440969. doi:10.1001/jamanetworkopen.2024.40969
Large language models are playing an increasingly significant role in medicine. This raises an important question: in clinical diagnosis, should LLMs be considered independent decision-makers or collaborative assistants to human physicians?
A randomized, single-blind clinical trial published in JAMA Network Open—conducted by a multi-institutional team from Stanford University, Harvard Medical School, and other institutions—revealed a pronounced disconnect between these two roles. The study found that while the independent diagnostic capabilities of LLMs significantly outperformed traditional resources—with a 16% improvement in scores—their use as assistive tools for physicians did not lead to a significant enhancement in diagnostic accuracy or efficiency. These findings indicate an intrinsic difference between the “independent intelligence” of LLMs and their “human-AI collaborative value,” which suggests that current technology has not effectively bridged the gap between physicians’ cognitive processes and the AI’s reasoning logic. Furthermore, the study noted that logical errors made by LLMs in complex cases could offset their theoretical advantages. In addition, physicians’ trust thresholds for AI recommendations, along with their cognitive load, emerged as critical limiting factors in the overall effectiveness of human-AI collaboration.
Academic Impact:
(1)Theoretical Innovation: Challenges the default assumption that AI assistance will inevitably improve clinical decision-making by introducing the concept of a “human-AI collaboration efficacy gap.”
(2)Technological Pathway: Calls for the development of “cognitive alignment” LLM architectures that prioritize enhanced model interpretability and seamless integration with physicians’ workflows.
(3)Clinical Practice: Clarifies that while LLMs are currently suitable for the preliminary screening of low-risk cases, human oversight remains essential in scenarios with high uncertainty.
(4)Policy Implications: Highlights the need to establish transparency standards and accountability frameworks for AI-assisted diagnostics to mitigate the risks associated with overreliance on such systems.
03. LLMs’ Predictive Ability in Neuroscience Surpasses Human Experts
Reference: Luo X, Rechardt A, Sun G, et al. Large language models surpass human experts in predicting neuroscience results. Nat Hum Behav. 2024;8(11):1435–1444. doi:10.1038/s41562-024-02046-9
The increasing complexity of neuroscience research and the exponential growth of literature have posed significant challenges to human experts’ capacity for information processing. With the advent of large language models (LLMs), a key question arises: can these models enable us to more accurately predict the outcomes of neuroscience experiments?
In a groundbreaking study published in Nature Human Behaviour, a research team led by Dr. Luo Xiaoliang demonstrated the immense potential of LLMs in forecasting neuroscience experimental results. The team developed a prospective benchmarking tool named BrainBench and created a specialized neuroscience model, BrainGPT, which leverages Transformer-based LLMs such as Llama2, Galactica, Falcon, and Mistral. By fine-tuning these models using LoRA (Low-Rank Adaptation), the researchers significantly enhanced their performance in the neuroscience domain. Their results showed that the LLMs achieved an average accuracy of 81.4% in prediction tasks, substantially higher than the 63.4% accuracy attained by human experts.
This study was supported by the Tianqiao and Chrissy Chen Institute, which provided crucial resources and platforms for advancing research in this field. The findings not only introduce a novel tool for neuroscience research, but also pave the way for deeper integration between artificial intelligence and scientific inquiry.
Academic Impact:
(1)Shift in Research Paradigms: The demonstrated predictive ability of LLMs suggests that future scientific research may increasingly depend on collaborations between AI and human experts, thereby accelerating scientific discovery.
(2)Tool Development and Application: The creation of BrainBench offers a standardized method for evaluating the performance of LLMs in scientific research, while BrainGPT provides a robust predictive model for neuroscience with potential applications in experimental design and data analysis.
(3)Information Integration and Innovation: By synthesizing background, methodologies, and conclusions from extensive literature, LLMs can uncover hidden patterns, offering new perspectives and insights for scientific research.
(4)Role of Human Experts: Despite the superior predictive performance of LLMs, researchers emphasize that human experts remain indispensable for scientific interpretation and theoretical development. The future of research will likely hinge on a synergistic blend of human insight and LLM capabilities.
02. Machine Learning-Based Probabilistic Weather Forecasting
Reference: Price I, Sanchez-Gonzalez A, Alet F, et al. Probabilistic weather forecasting with machine learning. Nature. 2024;526(7573):415–422. doi:10.1038/s41586-024-08252-9
Accurate weather forecasting is crucial for public safety, energy planning, and economic decision-making. However, traditional numerical weather prediction (NWP) has limitations in handling uncertainty. Can machine learning (ML) surpass traditional NWP in probabilistic weather forecasting by offering more accurate and efficient predictions?
In a recent study published in Nature, the DeepMind team introduced a probabilistic weather model called GenCast. GenCast is built on a diffusion model architecture and trained on ERA5 reanalysis data (1979–2018). It can generate a global ensemble forecast for 15 days within 8 minutes at a resolution of 0.25°, covering more than 80 surface and atmospheric variables. In tests involving 1,320 combinations of variables and lead times, GenCast outperformed the European Centre for Medium-Range Weather Forecasts (ECMWF) ensemble prediction system (ENS) in 97.2% of cases. It particularly excelled in predicting extreme weather, tropical cyclone tracks, and wind energy production. This research paves a new path for operational weather forecasting, enabling more accurate and efficient decision-making in weather-related matters.
Academic Impact:
(1)Forecasting Paradigm Shift: GenCast marks the transition from traditional numerical simulation to machine learning-based probabilistic prediction in weather forecasting.
(2)Enhanced Decision Support: By delivering more accurate probabilistic forecasts, GenCast improves our capacity to respond to extreme weather events.
(3)Increased Computational Efficiency: GenCast significantly boosts forecasting efficiency and reduces computational costs.
(4)Expansion of Scientific Research: This study offers fresh insights for developing future meteorological models, advancing the technology of weather forecasting.
01. Cross-sectional Comparative Study: LLMs’ Clinical Knowledge and Reasoning in Ophthalmology Approach Expert-Level Performance
Reference: Thirunavukarasu AJ, Mahmood S, Malem A, et al. Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study. PLOS Digital Health. 2024;3(4):e0000341. Published 2024 Apr 17. doi:10.1371/journal.pdig.0000341
Ophthalmology—a medical field that heavily relies on accumulated experience and dynamic decision-making—has long faced the global challenge of scarce and unevenly distributed expert resources. Can large language models (LLMs) reach expert-level performance in clinical knowledge and reasoning within ophthalmology?
A cross-sectional study published in PLoS Digital Health by a team from the Singapore National Eye Centre and the National University of Singapore revealed both the performance limits and the potential value of LLMs in specialty medicine. The study found that advanced LLMs—exemplified by GPT-4—have already achieved clinical knowledge and reasoning abilities that approach the median level of ophthalmology experts. Their responses were significantly more accurate and relevant than those of other models and non-specialist physicians. In specific subspecialty tasks, such as differentiating retinal diseases, they performed nearly at the level of seasoned experts. However, notable differences remain in the knowledge profiles of LLMs and human doctors. While LLMs exhibit systematic shortcomings in emergency management and individualized treatment recommendations, human doctors tend to be more affected by experience-driven biases. This paradox indicates that LLMs should currently be positioned as “supplementary expert capabilities” rather than outright replacements, with their core value lying in bridging resource gaps rather than disrupting clinical decision-making paradigms.
Academic Impact:
(1)Defining Technological Boundaries: Establishes the “quasi-expert” performance ceiling for LLMs in specialty medicine, clarifying their role in standardized knowledge retrieval and preliminary screening of non-emergency cases.
(2)Innovative Resource Allocation: Offers low-cost, highly accessible “virtual ophthalmology advisors” for regions with limited medical resources, thereby alleviating global disparities in eye health.
(3)Insights into Cognitive Science: Highlights the fundamental differences between human experts’ experience-driven decision-making and LLMs’ probabilistic reasoning, fostering the design of “human-AI complementary” clinical pathways.
(4)Iterative Validation Paradigms: Advocates for a dual-stage evaluation system—comprising specialty competency benchmarking and dynamic clinical feedback—to mitigate the risks associated with technological overreach.