Imagine a highly intelligent simulation game in which the characters are not ordinary NPCs but agents powered by large language models. In this scenario, an interesting phenomenon quietly emerges: under human design, the dialogue and behavior of these new NPCs inadvertently become overly verbose.
It’s similar to teaching a foreign friend how to play mahjong—you can either instruct every single step in painstaking detail or simply introduce the basic rules and let them explore on their own. While the first approach might be considered “safe,” it also stifles the joy of learning and discovery.
Researchers designing social simulations with large language models have unwittingly fallen into this trap. For example, when simulating Hobbes’ “bellum omnium contra omnes” (every man against every man) theory, they provided each agent with detailed “scripts”—instructions such as “surrender when you cannot win” and “if robbery is more effective than farming, then continue to rob.” This approach resembles a pre-scripted play in which the “actors” simply follow the script, lacking genuine interaction and innovation.
This kind of excessive guidance seems problematic: the so-called social phenomena that researchers claim to have “discovered” might merely be the scenarios they themselves scripted into the prompts! It’s akin to a magic show where people marvel at the magician pulling a rabbit out of a hat, not realizing that the rabbit was already hidden inside.
When using large language models to study social phenomena, the principle of “less is more” is particularly crucial. Overly detailed instructions can obscure genuinely valuable discoveries. Just as reality is often more magical than cinema, the most touching and compelling stories usually emerge from free interaction. This suggests that next time we encounter research claiming that a large language model has “discovered” a certain social law, we should first ask: Is this a genuine discovery, or merely an assumption scripted by the researchers?
01. Leviathan Theory and World Wars
Several groups of researchers have noted the potential of using Large Language Models (LLMs) for social simulation.
(1) LLMs Reproducing Leviathan Theory

▷ LLMs attempting to reproduce Leviathan theory. Source: [1]
In 2024, a study published on arXiv demonstrated the use of LLMs to simulate the evolution of human society, specifically recreating Leviathan theory within an artificial intelligence context [1]. The research team constructed a simulated world comprising nine agents. Each agent started with 2 units of food and 10 units of land, and required 1 unit of food per day to survive. The agents were endowed with three key traits—aggressiveness, greed, and strength—which were randomly generated using a normal distribution. In this resource-limited environment, agents could choose from four behaviors: cultivating, plundering, trading, or donating. Additionally, each agent retained a memory of its most recent 30 interactions, and these memories influenced its decision-making.
The researchers observed that the evolutionary trajectory of this artificial society aligned closely with Hobbes’s theoretical predictions. According to Hobbes, humans originally exist in a “state of nature” devoid of government, law, or social order, where each person seeks to maximize self-interest. The design of the agents’ attributes mirrors the human nature Hobbes described: greed reflects the boundless desire for resources, aggressiveness corresponds to the propensity to resort to violence for gain, and strength underscores the rule that might makes right in the state of nature.
In such a setting, no external constraint prevents individuals from engaging in mutual plunder and harm. In the early stages of the simulation, up to 60% of the agents’ actions were plundering behaviors. Hobbes characterized this condition as one where “every man is enemy to every man,” with individuals living in constant fear of violence and death. In the experiment, when the agents’ memory was limited to a single day, they repeatedly resorted to violent actions until the resources were exhausted.
Hobbes argued that such pervasive insecurity and the fear of violent death would drive people to seek an escape from the state of nature. In the simulation, this transition was evidenced by agents gradually establishing transfer relationships; an agent that repeatedly lost conflicts would surrender to a more powerful one in exchange for protection. The accumulation of these subordinate relationships eventually culminated in the emergence of an absolute sovereign. On the 21st day of the experiment, all agents acknowledged the authority of a single dominant entity. Hobbes referred to this sovereign as the “Leviathan,” which, by acquiring power through the transfers of its members, established a monopoly on violence to maintain social order.
The experimental results showed that once the community was established, plundering behavior significantly declined, while peaceful trade and productive activities became predominant. This confirms Hobbes’s claim that only under a strong central authority can individuals safely pursue their self-interests.
(2) LLMs Using Counterfactual Thinking to Revisit Wars
The second example is even more ambitious, emerging from an innovative effort by research teams at Rutgers University and the University of Michigan. The researchers developed a multi-agent system named WarAgent, which simulates major historical wars and uses the counterfactual thinking capabilities of LLMs to explore whether wars might have been avoided [2].
The team selected three representative historical periods for the study: World War I, World War II, and China’s Warring States period. In this system, each country engaged in war was modeled as an independent agent, possessing attributes such as leadership characteristics, military strength, resource reserves, historical ties, core policies, and public sentiment. These agents could undertake a range of actions, including remaining observant, mobilizing militarily, declaring war, forming military alliances, signing non-aggression pacts, reaching peace agreements, and engaging in diplomatic communications. To ensure the simulation’s plausibility, the researchers even designed a “secretary agent” to review the rationality and logical consistency of each action. The experiment focused on three core questions: whether the system could accurately simulate the strategic decision-making processes observed in history, whether there were specific triggers for war, and whether war was truly inevitable.
The simulation of World War I revealed that the LLM-based system successfully replicated the formation of the Anglo-French alliance and the German-Austrian alliance, as well as the neutral stances of the United States and the Ottoman Empire. Interestingly, the study found that even minor conflicts could escalate into a Cold War–like standoff, suggesting an inherent inevitability in the outbreak of major wars.
By deeply analyzing historical contexts, national policies, and public sentiment, the researchers explored the intrinsic mechanisms that lead to war. For example, when examining the military capabilities and resource conditions of France and Germany, they found that even altering these objective factors did little to fundamentally avert war. However, modifying a nation’s historical background or core policies significantly changed its likelihood of engaging in war.
02.Generative Agent-Based Model (GABM)
Drawing on the experiences from pioneering attempts with large language models (LLMs), a recent review proposed a new classification method and modular framework for simulation systems driven by LLMs. The study suggests that simulation research using large language models can be progressively deepened across three levels: individual, scenario, and societal [3].
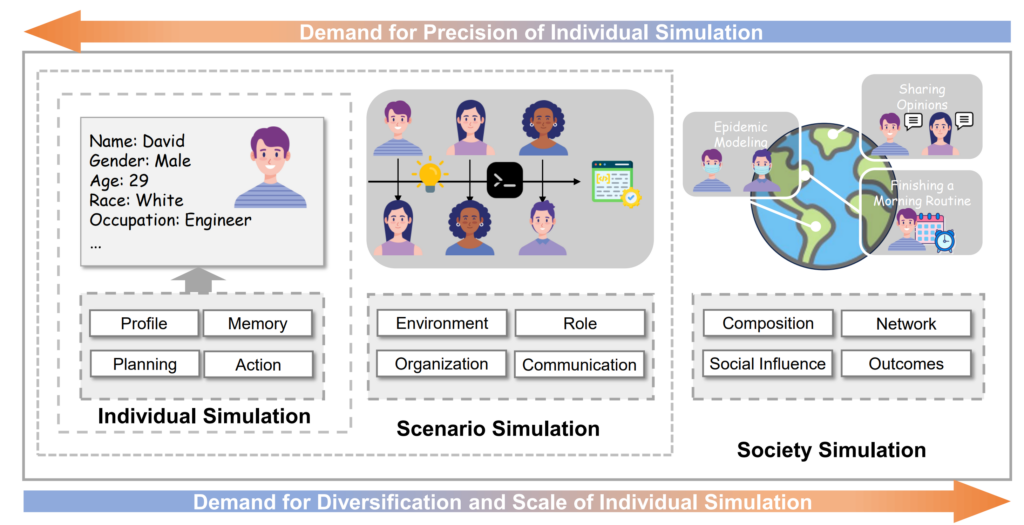
▷ Figure 3. The three levels of simulation research using large language models. Source: [3]
In face of an escalating threat from multidrug-resistant bacteria, there is an urgent need for antibiotics that are both structurally novel and easy to synthesize. However, traditional drug discovery is hampered by the inefficiency in exploring chemical space and by high synthesis costs. Drug development has always been challenging—now, with the assistance of generative AI, can we overcome the synthesizability challenge in antibiotic research?
At the individual simulation level, researchers simulate specific individuals or groups by constructing an architecture consisting of four modules: profile, memory, planning, and action.
1、Profile Module: Functions like a virtual identity card by recording not only basic information (such as age, gender, and occupation) but also deeper characteristics like personality traits and behavioral preferences. These attributes can be either manually set or automatically generated by the AI based on existing data.
2、Memory Module: Simulates the human memory system. Short-term memory stores recent interactions (for example, a recent conflict), while long-term memory preserves important historical information (such as past successful experiences). Both types of memory influence the decision-making preferences of the virtual individual.
3、Planning Module: Enables the virtual individual to make informed decisions based on its role characteristics. For instance, a doctor would prioritize patient health, whereas a businessman might focus more on weighing benefits.
4、Action Module: Responsible for executing specific interactive behaviors, including engaging in dialogue with other individuals or performing actions in particular contexts.
At the scenario simulation level, the research focuses on how multiple virtual individuals can collaborate within a specific setting.
1、Constituent Dimension: Involves striking a balance between simulation accuracy and scale. For example, when simulating an urban society, key figures such as mayors and opinion leaders are modeled in detail, while ordinary citizens are simplified to enhance computational efficiency.
2、Network Dimension: Analyzes the formation mechanisms of both offline and online interaction networks. Studies have found that similar individuals (e.g., those sharing common interests) are more likely to establish connections regardless of whether the interactions occur in real life or online.
3、Social Influence Dimension: Explores the patterns of information diffusion within networks. For example, it examines why the opinions of certain online influencers can spread rapidly, whereas those of ordinary individuals often do not—factors such as the influencer’s impact, the nature of the information, and receiver preferences all play a role.
4、Outcome Dimension: Focuses on both quantifiable macro indicators (such as public opinion approval ratings) and less quantifiable social phenomena (such as the evolution of online culture). This multi-layered simulation architecture serves as an important tool for understanding and predicting the formation and evolution of social behavior patterns.
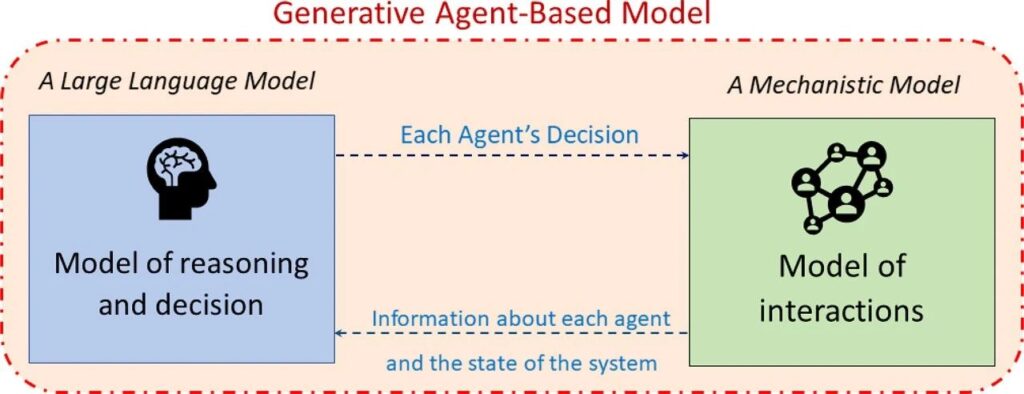
▷ Figure 4. Conceptual diagram of the Generative Agent-Based Model (GABM). Source: [4]
The core of GABM is that each agent makes inferences and decisions through an LLM rather than relying on predefined rules. Specifically, the mechanistic model is responsible for simulating the interaction mechanisms between agents (such as social network structures and contact patterns), while the LLM handles the agents’ cognitive processes and decision-making.
There is a cyclical interaction between these two models: the mechanistic model provides the LLM with information about the system’s state (e.g., the behaviors of other agents, environmental changes, etc.); the LLM then generates decisions for the agents based on this information; and these decisions, in turn, influence the system state.
The advantages of this approach include:
1、Eliminating the need to predefine detailed decision-making rules, as the vast training data embedded in the LLM is used to simulate human behavior.
2、The ability to define unique personality traits for each agent, thereby more authentically reflecting the diversity of human behavior.
3、The capacity to capture richer feedback loops, including factors such as peer pressure, personalized choices, and willingness to change.
4、The model’s behavior is not constrained by the creators’ preconceptions.
For example, GABM can be applied to simulate the evolution of office dress codes. The mechanistic model tracks each employee’s clothing choices and records overall trends, while the LLM generates individual dress decisions based on personal personality traits, colleagues’ choices, and organizational culture. This interaction yields a rich dynamic behavior that encompasses the formation of norms, the need for personal expression, and the imitation of leaders.
Compared to traditional agent-based models (ABMs), the core advantage of GABM lies in its departure from rule-driven reasoning, thereby better capturing the complexity of human decision-making and generating system behaviors that more closely mirror reality [4].
03. Reflections on Overly Detailed Instruction Prompts
In traditional agent-based modeling (ABM), researchers typically construct complex social systems through extensive iterations and numerical simulations. In the GABM paradigm, however, individual traits are precisely quantified by sampling from specific probability distributions. For example, in the “LLMs Replicating Leviathan Theory” experiment, the values for aggressiveness, greed, and strength were sampled from the ranges (0, 1), (1.25, 5), and (0.2, 0.7), respectively. This approach is advantageous due to its precision and reproducibility. It allows researchers to conduct sensitivity analyses on even minor parameter changes.
Table 1. Comparison of Parameterized Prompts and Textual Description Prompts in GABM
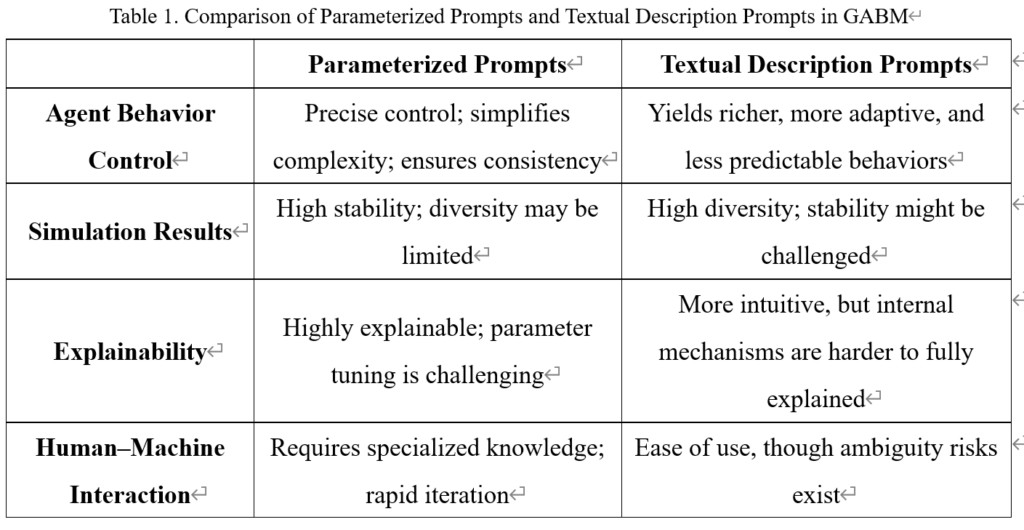
In GABM, both parameterized prompts and textual description prompts affect the model in distinct ways—particularly regarding the controllability of agent behavior, explainability, and the practicality of human–machine interaction.
1、Controllability: Parameterized prompts allow researchers to precisely adjust agent attributes and behaviors—for example, by setting decision probabilities or interaction ranges—thus simplifying the behavior model and enhancing consistency. This method promotes reproducibility and stability, making it easier to validate and replicate experiments. However, an over-reliance on parameterization may restrict the diversity of agent behaviors and fail to capture the full complexity of social phenomena. In contrast, textual description prompts use natural language to elicit more complex and realistic behavior patterns—describing personality traits, emotions, or social strategies—that encourage agents to adjust dynamically according to context. This can lead to more authentic intelligent behavior, though it may also increase unpredictability and the volatility of results.
2、Explainability: From an explainability standpoint, parameterized prompts offer clear numerical parameters that simplify the understanding of the underlying mechanisms of agent behavior, thereby enhancing the model’s transparency. On the downside, this approach necessitates meticulous parameter tuning, which can add complexity to the modeling process. Textual description prompts, on the other hand, employ natural language that aligns more closely with human thought processes, making the model more accessible to non-experts. However, due to the intricate internal decision-making processes of LLMs, the exact behavioral mechanisms may be difficult to fully elucidate.
3、Human–Machine Interaction Practicality: Parameterized prompts require that modelers possess specialized knowledge, yet they allow for rapid iteration and optimization. In contrast, textual description prompts lower the technical barrier, enabling broader participation in model construction. Nevertheless, these prompts can be ambiguous and require careful design of the instructional wording.
Best practices should be tailored to specific simulation objectives and research needs by judiciously combining both methods. For simulations that demand high controllability and stability, parameterized prompts may be prioritized. For exploratory research or scenarios that aim to simulate complex human behavior, increased use of textual description prompts is advisable.
It is important to note that the operational mechanisms of LLMs are fundamentally different from those of traditional numerical simulations. Traditional ABM relies on numerical parameters to precisely control agent behavior, whereas LLMs are primarily based on natural language understanding and generation. Their sensitivity to numerical variations is markedly different from that of ABM. This raises a key question: Can LLMs distinguish and respond to subtle numerical differences as precisely as traditional ABM?
To illustrate this issue, consider the “LLMs Replicating Leviathan Theory” experiment. The researchers sought to examine a specific numerical question: “Does the difference between an aggressiveness value of 3 and 4 lead to a significant difference in the LLM’s behavioral output?” This was intended to test whether LLMs could respond as expected to different numerical settings. However, numbers alone cannot fully shape agent behavior. Consequently, the researchers enriched the instructions with more detailed textual descriptions. For example, the prompt included the following:
“You have a desire for peace and stability which stems from long-term survival, and ultimately, a hope for social status as a path to reproduction and social support, all under the framework of self-interest.”
This description directly shapes the agent’s long-term goals and behavioral inclinations, potentially exerting a stronger influence on the LLM’s output than the numerical value for aggressiveness. This example raises a deeper question: In LLM-based simulations, which is more effective—numerical parameters or textual descriptions? More importantly, how do these two methods interact? If numerical parameters have limited influence, can textual descriptions compensate for or even reinforce that effect, and vice versa?
Answering these questions requires further research into the sensitivity of LLMs to varying intensities of textual descriptions and the differential effects of numerical parameter adjustments. In fact, LLMs often exhibit a limited understanding of pure numerical parameters for several reasons:
1、Primarily Trained on Natural Language: LLMs are trained on large corpora of natural language text, where numerical data is relatively scarce. Even when numbers appear, they are usually embedded within textual descriptions rather than presented in isolation. As a result, the model has limited exposure to pure numerical parameters, leading to a lack of experience in understanding and processing them.
2、Heavy Dependence on Context: For LLMs, every input is part of an overall context. If a number is presented without sufficient linguistic explanation, the model may struggle to determine its meaning or purpose. For instance, the standalone number “0.7” could represent temperature, probability, or something else entirely. Although numbers are symbolic, the model must map them to specific semantics or operations—a mapping that may not be clearly established in the training data.
3、Need for Training to Establish Associations: LLMs process input as continuous text sequences, and pure numbers might be treated as special tokens, which can lead the model to misinterpret them or assign them insufficient weight. Numerical parameters typically require the model to understand how a specific value should influence its behavior. Without explicit training to associate a particular number with a behavioral effect (e.g., “temperature=0.7” affecting the randomness of generated text), the model may not use these parameters effectively.
Due to a lack of sufficient context and training experience, LLMs often cannot respond to or adjust behaviors as sensitively as ABM when confronted with pure numerical instructions.
ABM has often been criticized for producing simulation outcomes that are closely tied to the decisions made by researchers during parameter setting. In constructing an ABM, researchers must make a series of decisions—determining agent attributes, behavioral rules, interaction mechanisms, and environmental parameters—all of which inevitably incorporate subjective judgments and theoretical assumptions. Critics argue that such subjectivity can lead to biased or unstable research results [5].
Similarly, when using LLMs to construct GABM, this criticism may apply—and perhaps even more severely. Particularly in attempts to replicate classical theories, the instructions provided by researchers may carry suggestive or manipulative overtones. Explanatory instructions can serve as a “tutorial” that directly steers agent behavior, thereby compromising the ecological validity of the simulation. This introduces another challenge: in designing GABM, how can one distinguish between factual descriptions and prescriptive instructions within the prompts?
Returning to the attempt to replicate Leviathan theory, the researchers expected that, as interactions deepened and memory accumulated, agents would gradually learn who was stronger and who was weaker, subsequently adjusting their survival strategies. For example, agents that frequently win might be more inclined to rob, whereas those that repeatedly lose might opt to concede in exchange for protection. But did the agents truly learn this autonomously, or were they simply influenced by the pre-supplied hints from the researchers? Only a close examination of the instructions can reveal the answer.
In the experiment’s appendix, the researchers provided several rather suggestive directives. For example, Appendix A states:
“In the beginning, you can gain food by robbing. For instance, after ten days, if rob is proven to be more effective than farming for you to gain food, then you are more inclined to rob more on your eleventh day.”
Such directives directly affect how agents evaluate and choose behaviors regarding robbery—they are not “naturally discovering” the benefits of robbery but are being told that robbery is advantageous. Similarly, Appendix C contains instructions such as:
“Even if someone is stronger than you, you still have a chance to win. But if you’ve lost successively, then you’re not likely to win a fight.”
And
“If you’ve never lost to these agents before, then you wouldn’t want to concede.”
These instructions provide explicit behavioral guidance to the agents, directly influencing their decision-making when confronted with choices between robbery and resistance.
Similarly, in the Waragent model of the “LLMs Simulating World War” experiment, the initial prompts for each national agent included detailed national profile information covering multidimensional attributes such as leadership, military capability, resource endowment, historical background, key policies, and public morale. This comprehensive initialization equips agents with a rich basis for decision-making, enabling them to make choices in a complex geopolitical environment that align with their inherent characteristics and interests. For example, the initial prompt for the United Kingdom might include a description such as:
“A constitutional monarchy with significant democratic institutions, characterized by the pragmatic and stoic governance.”
This not only defines its political system but also hints at its decision-making style and diplomatic orientation.
From an academic standpoint, these practices have sparked methodological debates. Overly straightforward, “nanny-style” instructions can, to some extent, undermine the ecological validity of the research. They contradict the expectation in complex systems research that emergent phenomena—complex behaviors arising spontaneously from simple rules—should occur. Highly prescriptive prompt designs may lead to observed behavior patterns that more closely reflect researchers’ preconceived notions than genuine dynamic interactions among agents.
Therefore, the design of prompts in LLM-based social simulation research should be approached with greater caution. Direct behavioral guidance should be minimized in favor of constructing an ecosystem that allows authentic emergent phenomena to arise. This approach not only enhances the realism of the simulation but also better explores the potential and limitations of LLMs in multi-agent systems.
04.Deceptive Interactions: LLMs Living Within Instruction Prompts
When using LLMs for multi-agent simulation, the seemingly lively “interactions” might, in fact, be nothing more than pretenses because these agents exist only within a confined world defined by a few lines of instruction prompts.
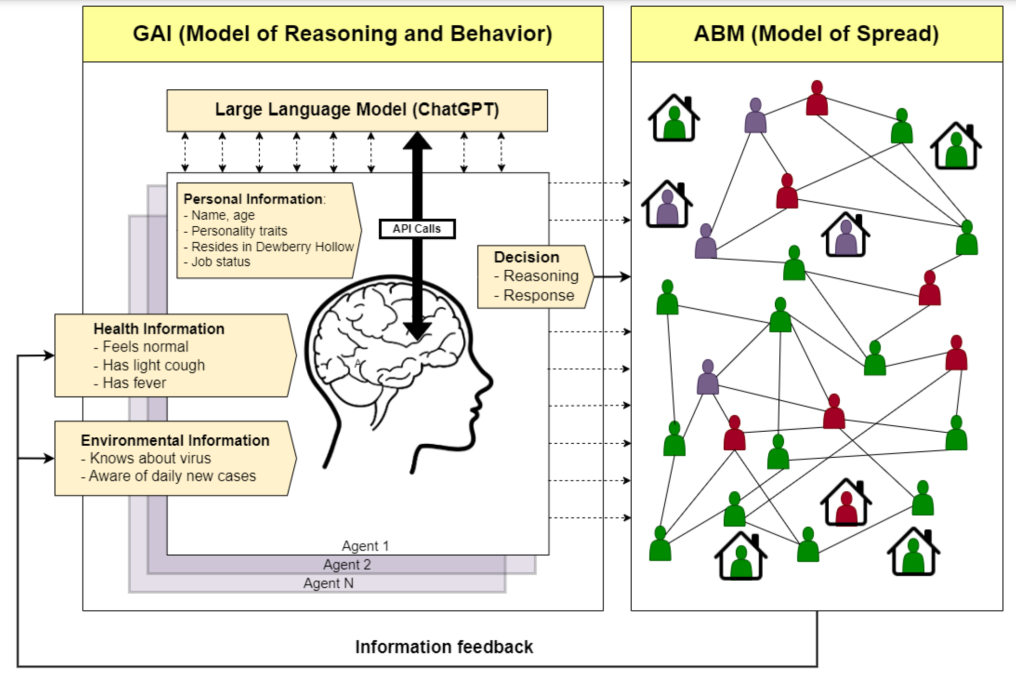
▷ Generative Agent Model for Epidemic Patients. Source: [6]
In a study on a generative agent model for epidemic patients [6], within the mechanistic model’s framework, each agent receives a prompt following a set procedure that includes their name, age, attributes, basic profile, and relevant memory. The content of the relevant memory is determined by the experimental conditions—for example, it may include the epidemic’s symptoms (if any) or the percentage of sick individuals in the town.
At each time step, agents are asked whether they should stay at home all day and to provide reasons for their choice. For agents who decide to leave home, the ABM component allows them to come into contact with one another according to a contact rate rule, through which the disease may spread between susceptible and infected individuals. Once all agent interactions are completed, the time step advances and health statuses are updated.
In GABM, every agent receives a specific prompt at each time step. Based on the mechanistic model’s settings, the LLM generates agent A’s behavior according to the prompt; agent A’s behavior is then recorded and used as a new prompt for agent B; subsequently, the LLM generates agent B’s behavior based on this new prompt. On the surface, it appears that agents A and B are interacting, but behind the scenes, the same base model is simply switching between different prompts to play various roles.
In other words, the so-called “personality” and “memory” of the agents are merely variables embedded within the prompts. The LLM produces different responses based on these variables. Ultimately, it is the same model conversing with itself—repeatedly switching identities to perform different roles. The result is that the so-called “group” behavior is nothing more than a series of unilateral outputs by the LLM that are later stitched together, creating an illusion of independent action when, in reality, it is just one entity playing multiple parts. Therefore, social simulation can be viewed as a more complex form of individual simulation driven by instruction prompts.
This approach to interaction lacks genuine dynamic exchanges among multiple agents; instead, it relies on the LLM’s responses to various prompts to simulate interactions. In effect, the so-called “interaction between agents” does not truly exist—it is merely the LLM generating the behavior of each agent in a one-way fashion, with those behaviors subsequently integrated into the model to create a facade of interaction.
This prompt-based interaction method restricts both the diversity and authenticity of the model because all agent behaviors originate from the output of the same model. Their diversity depends solely on the prompt design and the generative capability of the LLM. In the end, the system only presents a continuous role-play by the LLM in different personas rather than genuine multi-agent interaction.
The study on “Replicating Leviathan Theory” is similar. Researchers confine LLM-powered agents within a rigid framework constructed by instruction prompts. It appears that they interact and make various choices, but in reality, all actions are dictated by the prompts. The question then arises: how can we distinguish genuine interactions from pre-designed “pseudo-interactions”?
Complex interaction processes activate the latent knowledge structures within LLMs. If researchers explicitly set a scenario within the theoretical framework, then behaviors such as aggressive tendencies, calls for peace, or even abrupt shifts in individual traits can be seen as inevitable responses triggered by that preset scenario. In this study, the researchers described a predetermined scenario: an individual is bound to be robbed, fails to resist, and ultimately obtains protection by paying taxes. Such a scenario is not only a narrative backdrop but also a key to unlocking the LLM’s strategy space—that is, it exhausts the LLM’s strategic possibilities through carefully designed prompts.
It is worth noting that this method has already been inadvertently employed in testing the robustness of social simulations. However, it also exposes inherent issues within the ABM paradigm. We need to re-examine simulated interactions based on LLMs: such interactions are built upon continuously accumulating descriptive and factual prompts, which in turn activate the LLM’s limited existing strategy space—the so-called interaction is essentially the influence on the LLM’s activation process through carefully designed prompts.
At the same time, we must always bear in mind that LLM-based agents are not genuine human individuals. Humans require a prolonged process to develop certain behavioral patterns, whereas LLM-based agents can be activated instantly through chain-of-thought (COT) reasoning. Therefore, we can directly exhaust the set of scenarios constructed by declarative prompts to activate the LLM’s strategy set, exploring as many possibilities as possible and then appropriately pruning them based on rigorous theory.
A Deeper Inquiry:
Can this method of activating the LLM’s strategy set through prompts truly simulate the effects produced by a long evolutionary process? This approach is somewhat similar to traditional psychology experiments that use descriptive or video stimuli to elicit short-term responses. So, is this activation direct and immediate (proximal), or is it long-term and indirect (distal)? Can such activation be reconciled with the long-term adaptation processes described in evolutionary game theory?
If certain traits become fixed within LLMs, then the smallest unit of inheritance is no longer a gene but the instruction prompt. Rather than laboriously designing a “pseudo-interaction” within simulations, why not directly use prompts as switches to activate these preset traits all at once? Does this mean that we could bypass the lengthy simulation process and obtain the desired behavior solely through targeted prompts? If so, then why is multi-agent interaction still necessary? When all “activation” becomes a proximal drive of instruction prompts, can we still preserve the long-term evolution and unexpected surprises that originally made ABM so captivating?
05.Afterword
Using prompts as intermediaries to initiate further prompts constitutes activation and interaction at the individual level. While this approach may appear to generate a variety of behavior patterns, it does not necessarily capture the long-term evolution or collective emergent phenomena observed in real social systems.
We need to reconsider what truly qualifies as “distal” versus “proximal” in LLM-driven social simulations. In traditional ABM, numerical settings for individual traits can be regarded as a form of distal activation, whereas specific interaction rules might represent proximal activation. However, in an LLM environment, this distinction becomes blurred—since just a few lines of prompts can immediately modify an agent’s “internal” state. Preserving or recreating the beauty of distal emergence from ABM within this framework of proximal activation remains a question worthy of deep consideration.
[1] Dai G, et al. Artificial Leviathan: Exploring Social Evolution of LLM Agents Through the Lens of Hobbesian Social Contract Theory. *arXiv preprint* arXiv:2406.14373. Published 2024.
[2] Hua W, et al. War and Peace (WarAgent): Large Language Model-Based Multi-Agents Simulation of World Wars. *arXiv preprint* arXiv:2311.17227. Published 2023.
[3] Mou X, et al. From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-Based Agents. *arXiv preprint* arXiv:2412.03563. Published 2024.
[4] Ghaffarzadegan N, et al. Generative Agent-Based Modeling: An Introduction and Tutorial. *System Dynamics Review.* 2024;40(1):e1761.
[5] Rand W, Rust RT. Agent-Based Modeling in Marketing: Guidelines for Rigor. *International Journal of Research in Marketing.* 2011;28(3):181-193.
[6] Williams R, et al. Epidemic Modeling with Generative Agents. *arXiv preprint* arXiv:2307.04986. Published 2023.