Cognitive science traditionally categorizes human behaviors and those of algorithm-driven agents into two types: one is goal-driven, like an explorer with a map who knows where they are headed; the other follows habits, like a student who consistently takes the same route to school. It has been generally accepted among researchers that these two types of behavior are governed by distinct neural mechanisms. However, a recent study published in Nature Communications proposes that both types of behavior can be unified under the same theoretical framework: variational Bayesian theory.  ▷ Han, D., Doya, K., Li, D. et al. Synergizing habits and goals with variational Bayes. Nat Commun 15, 4461 (2024). https://doi.org/10.1038/s41467-024-48577-7
▷ Han, D., Doya, K., Li, D. et al. Synergizing habits and goals with variational Bayes. Nat Commun 15, 4461 (2024). https://doi.org/10.1038/s41467-024-48577-7
1. Question: The Same Domain, the Same Essence
In scientific research, whether studying animals, humans, or machine learning algorithms, we often encounter the question: When faced with a new environment or challenge, should we rely on instincts and habits, or should we try to learn new methods? This question may seem to span various fields, but in reality, these fields all revolve around a central issue: How to strike the optimal balance between rapid adaptation and maintaining flexibility.
For example, when animals face environmental changes, they may instinctively react by seeking shelter or searching for food—behaviors that may be innate or learned. Similarly, in decision-making, people sometimes rely on intuition (what psychologist Daniel Kahneman calls "System 1"), while other times they engage in more careful deliberation ("System 2"). In machine learning, some algorithms are "model-free," meaning they learn from experience without predefined rules, while others are "model-based," relying on explicit rules and models. 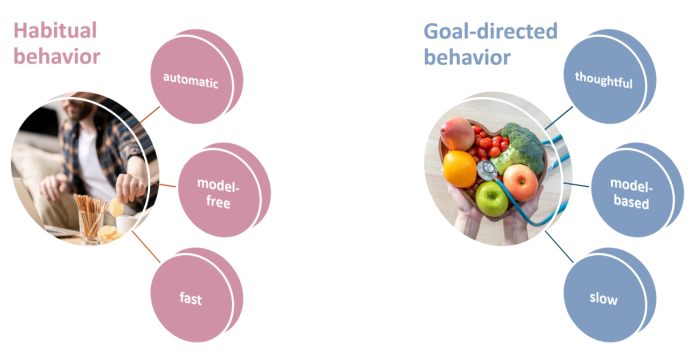 ▷ The characteristics of habitual behaviors (e.g., snacking while focused on work) and goal-directed behaviors (e.g., planning a diet meal).
▷ The characteristics of habitual behaviors (e.g., snacking while focused on work) and goal-directed behaviors (e.g., planning a diet meal).
These seemingly different situations are, in fact, quite similar: whether in biological or artificial systems, the key challenge is to balance rapid adaptation with flexibility in handling new situations.
For instance, bacteria quickly adapt to their environment through chemotaxis (the instinct to move toward nutrient-rich areas). When faced with an environment without pre-established rules, an intelligent agent may behave like a student immersed in solving problems, quickly reaching the goal. However, more complex organisms or algorithms may require more flexible strategies to tackle more sophisticated challenges.
To explain the process of goal-directed learning, neuroscientists have proposed the theoretical framework of active inference. This framework posits that the brain is constantly trying to minimize uncertainty and unexpected outcomes when predicting the environment by directing the body to interact with it. The core concept of this theory, "free energy," measures the difference between the probability of sensory inputs and the expected sensory inputs. The process of active inference is essentially the process of minimizing free energy.
While "active inference" provides insight into goal-directed learning, it remains a hypothesis that has yet to be fully validated in the scientific community. There is still insufficient empirical evidence to support the neural mechanisms behind it. For instance, active inference explains goal-directed behaviors as a process of minimizing the gap between goals and reality. However, it falls short in explaining habit-based behaviors that do not require conscious intervention or rely on external feedback.
Recent studies have attempted to demonstrate how these seemingly opposing behavioral modes, goal-directed and habit-driven, can work together within a unified theoretical framework, enabling organisms to efficiently and flexibly adapt to their environment.
2. Discovery: Predictive Coding and Complexity Reduction—The Brain's Ongoing Bayesian Inference
To better understand this new framework, we can liken the brain to a chef constantly experimenting with new dishes. When a chef adjusts his menu, is he making the dishes more appealing to customers or simply cooking out of habit? In reality, he is doing both. On the one hand, he reduces the gap between his culinary creations and the customers' tastes. On the other hand, he continuously updates and simplifies the predictive model of changing customer preferences—his expectations of their tastes.
This process can be illustrated with a simple example. A limited menu with only a few dishes may lack the flexibility to satisfy all customers' needs. In contrast, a complex menu that can be freely adjusted based on customer feedback might better accommodate different tastes, but it could become too complicated to manage, increasing costs or leading to inconsistent flavors.
Scientists have described this process in mathematical terms, defining "latent intentions" to expand the concept of free energy. In this context, free energy includes not only the concept from active inference but also the agent's behavioral tendencies and predictions about observations. The agent's learning behavior can be seen as a continuous updating process (Markov chain) aimed at minimizing the value of Zt. This value comprises prediction error (the discrepancy with reality) and KL divergence (the complexity of the model).

British cognitive scientist Andy Clark pointed out that the brain is a powerful prediction machine, constantly forecasting upcoming sensory inputs and adjusting these predictions based on actual inputs. In this process, the prediction error corresponds to the first term in the aforementioned formula. The second term, KL divergence, measures the difference in probability density between predictions before and after an action, reflecting the complexity of the predictive model. In habit-driven learning, whether an action is taken or not does not affect the prediction, making this term zero, meaning no model exists. Thus, KL divergence, which represents model complexity, turns the binary distinction between model-free and model-based approaches into a continuous spectrum.
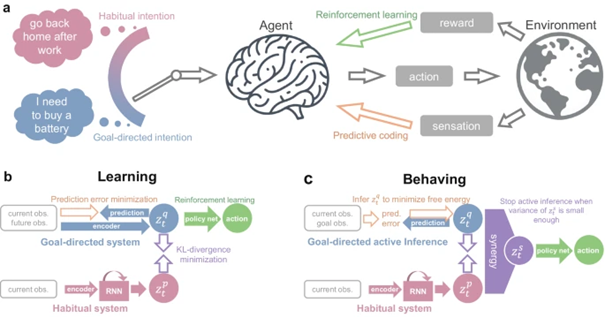
▷ a) Schematic of integrating habits and goal frameworks. b) Structure of the framework during training. c) Structure of the framework during behavioral processes.
In this framework, when faced with a new goal, early learning resembles a model-based system, similar to a chef who, upon opening his restaurant, tries to optimize his predictions of new customers' tastes. Once this predictive model has been sufficiently refined through continuous training, it may shift toward a more habit-driven approach, where the chef continually perfects his signature dishes.
3. Significance: Enabling AI to Perform Zero-Shot Learning
One significant advantage of human intelligence is the ability to solve various tasks in entirely new environments without relying on prior examples. For instance, when a painter is asked to depict a mythical creature like a qilin, he or she only needs to know that the qilin is a symbol of good fortune. However, an AI would require specific prompts, such as: "Depict a qilin from ancient Chinese mythology, with a dragon's head, deer antlers, lion's eyes, tiger's back, bear's waist, snake's scales, horse's hooves, and an ox's tail, exuding an overall aura of majesty and sanctity, with gold and red as the primary colors, against a backdrop of swirling clouds, symbolizing good fortune, peace, and imperial power."
The first painter to depict a qilin did so through zero-shot learning after acquiring sufficient experience in painting; however, zero-shot learning remains a challenging task for current AI systems. This is precisely the issue that this framework aims to address.
When the environment changes, an agent built using the integrated framework proposed in this paper can spontaneously switch from habit-based model-free learning to model-based learning. This allows the agent to adapt to the new environmental conditions. In their experiments, researchers used a T-maze to test the adaptability of these agents. In this maze, the agent must decide which direction to take based on rewards on either side, learning strategies to maximize rewards.
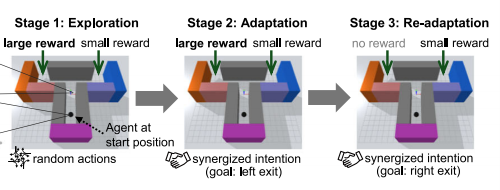 ▷ T-maze and the three stages of the agent in response to environmental changes.
▷ T-maze and the three stages of the agent in response to environmental changes.
In a habit-based system, the agent might continue following the previously rewarded path, even if the reward has changed. However, goal-directed agents face a different challenge. For example, if the initial reward on the left side of the maze is 100 times greater than on the right, the agent might need to try the left side a hundred times before updating the model and attempting the right side (depending on the specific agent model). This is undoubtedly an inefficient approach; in the real world, an organism displaying such behavior would likely be eliminated by natural selection. The framework proposed in this paper integrates goal-driven and habit-driven approaches, allowing the agent to balance flexibility and speed. Initially, it adapts to the environment by choosing the right side; when the environment changes (the left reward disappears), it readjusts to choose the left side.
The simple T-maze experiment shows that the new framework aligns with Yann LeCun's concept of the world model. LeCun emphasizes that a world model has a dual role of planning for the future and estimating missing observations, and it should be an energy-based model. In goal-directed behavior, this framework uses the current state, goal, and intended actions as inputs, and outputs an energy value to describe their "consistency." It can be said that the agent's decision-making in the T-maze builds upon and relies on the world model envisioned by LeCun.
There is a long road ahead from the simple T-maze to highly complex large language models. However, based on the theoretical framework described in this paper, we can observe some important similarities. For example, in training language models, we typically predict based on existing vocabulary, similar to scenarios without specific goals set during the training phase. The flexibility of goal-directed planning in this framework comes from its ability to break down any future goal into a series of sequential steps, predicting only the next observation. This method minimizes the discrepancy between goal-directed intentions and prior distributions, thereby compressing the search space and making the search process more efficient. This approach is also suitable for large models.
Additionally, based on the KL divergence term in the framework, we can understand the hierarchical structure in predictive coding, where a hierarchical information processing method is used to reduce model complexity. Predictive coding theory also suggests that the brain learns to recognize patterns by filtering out information that can be predicted through natural world patterns, thereby reducing unnecessary data. This information processing strategy echoes the information bottleneck theory, showing how cognitive processes can be optimized by using lower-dimensional representations.
Finally, this theoretical framework not only enhances our understanding of healthy brain function but also provides new perspectives for understanding and treating neurological disorders. For example, patients with Parkinson's disease often struggle with goal-directed planning abilities and rely more on habitual behaviors. This may be due to high uncertainty within goal-directed intentions. Research on how medical interventions or deep brain stimulation (altering internal states) and sensory stimulation (altering brain input) can reduce this uncertainty may provide methods to improve motor control in Parkinson's patients.
Moreover, research on autism spectrum disorder (ASD) can also benefit from this theoretical framework. Individuals with autism often exhibit repetitive behaviors, which may be related to an overemphasis on model complexity in predictive coding, affecting cognitive behavioral flexibility when adapting to changing environments. Introducing some randomness to increase behavioral diversity could be a potential intervention strategy.